为 AdSense 铺路:我如何修复 'GSC 重复网页' 与 Canonical 致命错误(Hexo, 301, robots 详解)
背景
之前 MCompass 项目的博文引来不少流量,Cloudflare 后台的数据看得我挺惊喜。原本想过把这个小装置做成产品,但版权和量产成本确实是个砍。于是我开始想,能不能通过 AdSense 这种成熟的平台,让这些流量转化成一点维护网站的服务器成本。
结果没想到,Google 在接连几次申请中都给我发了“需要采取行动”的回执。信里说申请需要调整,但具体的“痛苦面”在哪又没说清楚。
我意识到,单纯堆内容是不够的,站点的“技术卫生习惯”——也就是 SEO 和抓取合规性,可能已经烂透了。于是,我决定给博客做一次彻底的底层清理。
诊断:先看 Google 眼中的我
第一步,我必须搞清楚“谷歌眼中的我”是什么样, 搜索引擎有个专门指定搜索内容的命令叫做site, 用法就是在搜索内容前面添加site: xxx.com, 这样搜索到的结果就只会来自我们指定的站点.
site: 命令的“恐怖”现状
检索网站收录情况, 第一页内容中不仅没有根域名,还错误的收录了blog域名下的无关紧要的内容.
比如这个莫名其妙的”快来抢沙发吧!”的links地址, 再靠后则是compass域名的相关页面.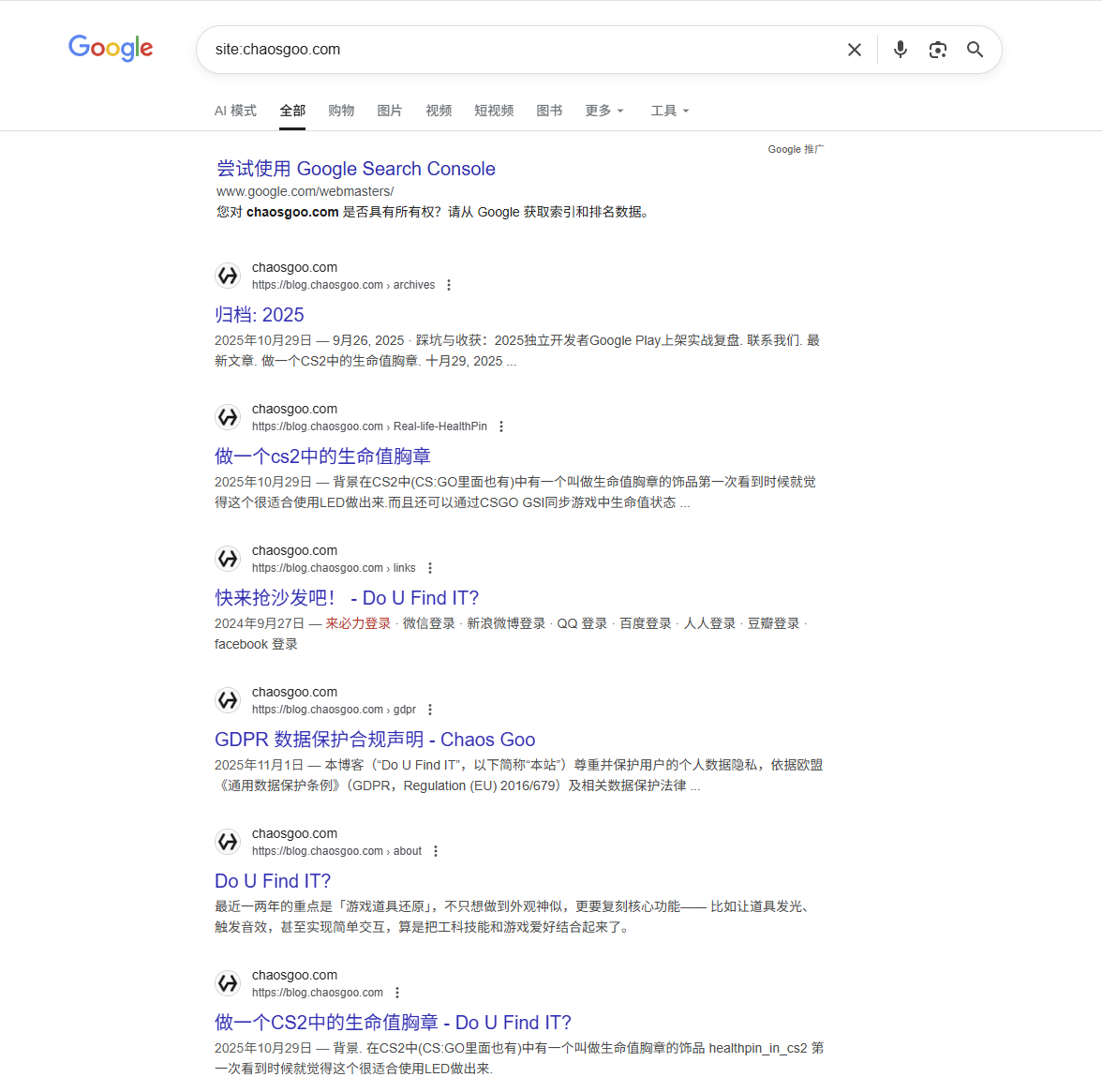
行动一:内容上的“断舍离”
删掉那些凑数的文章
翻了下旧档,发现几年前学 Kotlin 时写的笔记写得惨不忍睹。基本就是对着官方文档复读了一遍,再加上一堆没意义的自言自语。这些东西存电脑里自己看还行,放网上确实是在浪费爬虫的精力。
还有一些早期的 Blender 练习展示,只有几张图,没有技术细节。AdSense 想要的是具有原创深度的内容,这种“搬运感”很重的薄内容 (Thin Content) 必须清理掉。
虽说有点舍不得,但我还是“壮士断腕”,把文章从 58 篇砍到了 22 篇。
清理低价值文章
几年前, 我曾有过一段学习Kotlin的时光, 当时为了加深印象, 编写过一些学习Kotlin的笔记, 但是笔记基本上就是把官方文档的内容手动敲打了一遍.
而且还有很多自言自语, 这种文章对于其他人的帮助其实是微乎其微的, 适合存放到一些专门的笔记工具(如notion)中去, 所以是首要清理对象.
此外,在19~20年的一些日子, 我还使用Blender进行了创作.内容只是简单的分享创作结果, 没有深入制作技巧, 细节. 这种类型的文章也很有可能被判定为低价值文章,也要被纳入清理对象中.
AdSense 极其看重**‘原创价值’。像这种单纯‘搬运文档’或‘自言自语’的内容,极易被判定为‘内容单薄’ (Thin Content)**。为了不拖累整个网站的评分,我必须壮士断腕。
在仔细排查一番后, 从最开始的58篇文章, 减少到了22篇文章.
修复链接错误
在保留下来的这22篇文章里面, 由于博客多次迁移, 导致的里面的图片和视频链接失效了.
这个是不能容忍的, 因为爬虫会检测到, 所以能修复死链的一定要修复.
我的这个修复起来比较简单, 因为只是少了?raw=true, 补充即可.
文章内容优化
22篇文章中有些是属于原创性高, 但是内容略微简略, 我们可以对齐进行优化和扩充. 使其具有真实价值.
比如我的那篇CS2胸章文章中详细介绍了元件选型策略, Aurora新增Script Device方法.
行动二:解决那四个技术症结
1. 域名打架(301 重定向)
我的站域名变迁史有点乱。最开始在 blog.chaosgoo.com,后来又试过 www。申请 AdSense 时必须提交 root 域名(chaosgoo.com),导致现在搜索结果里充斥着一堆过期的二级域名,权重全分散了。
我的站点过去较长一段时间里部署在blog.上, root域名(chaosgoo.com)处于闲置状态.
在申请AdSense时候,要求填入的是root域名, 而非blog.域名, 所以几个月前,还专门迁移到了root域名.
再往前一段时间,网站也曾部署到www上, 所以site:命令检索到的结果能看到blog. 和 www. 两个“废弃”域名在“污染”索引。
为了提高root域名权重, 还有搜索结果的整洁清晰, 这两个旧域名要进行大清理一番.
旧域名处理
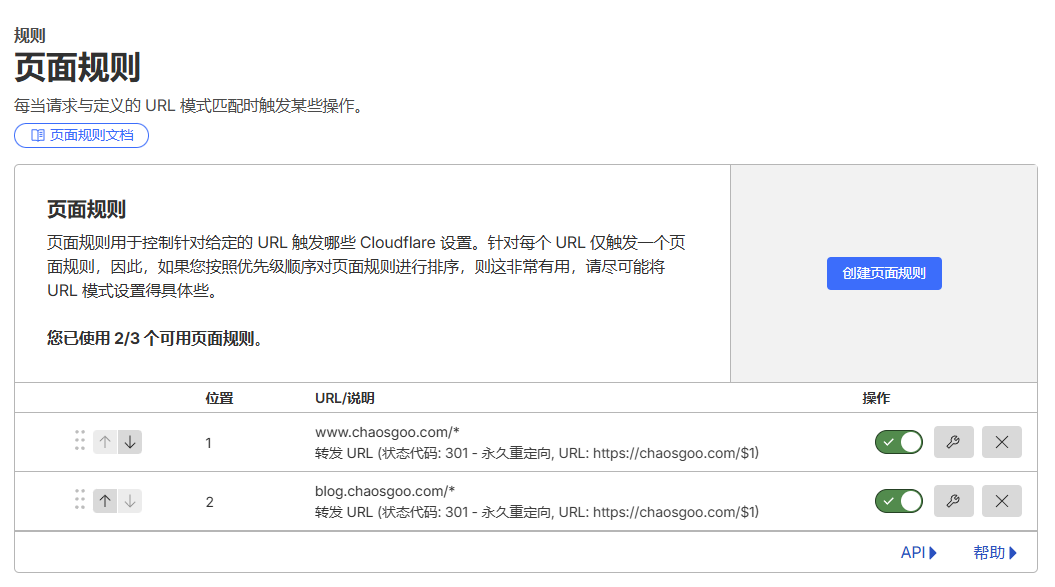
页面规则
感谢赛博大善人Cloudflare 提供了很多方便的工具.
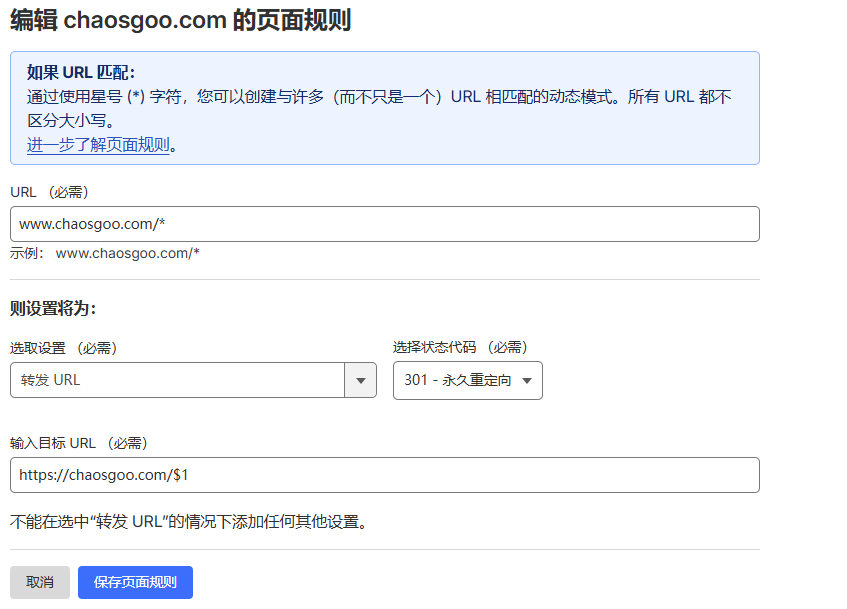
这里我们来到cloudflare的控制台,找到页面规则, 为www.和blog.两个旧域名添加重定向规则.
参数如下图所示:
Cloudflare 解析优化
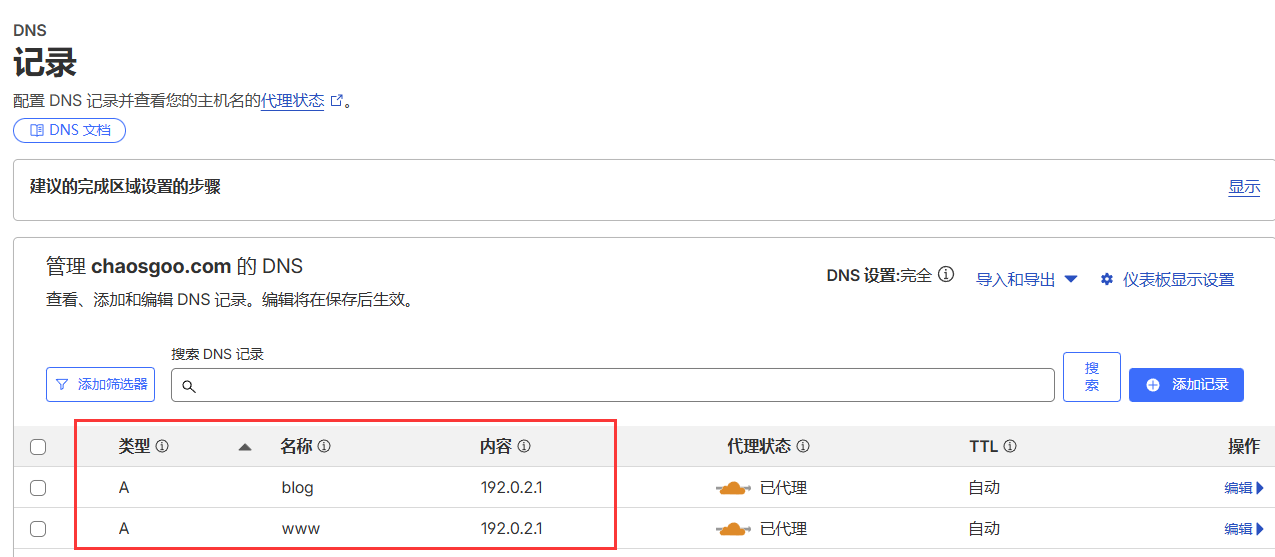
配置好页面规则以后, 并不是万事大吉了, 还需要在解析添加两条虚拟的A记录特别注意: 这条 A 记录的代理状态必须开启(点亮橙色云朵),否则 Cloudflare 的页面规则无法接管流量。重要:否则页面规则不会生效.
#2:索引污染(Robots 防火墙)
是否还记得前面使用site:命令看到的tags页面相关的无关内容
接下来我们要将其从搜索结果里面移除.
robots.txt内容优化
我们要主动告诉爬虫机器人, 这些页面是不需要的,请不要爬取这些内容.
编写如下robots.txt规则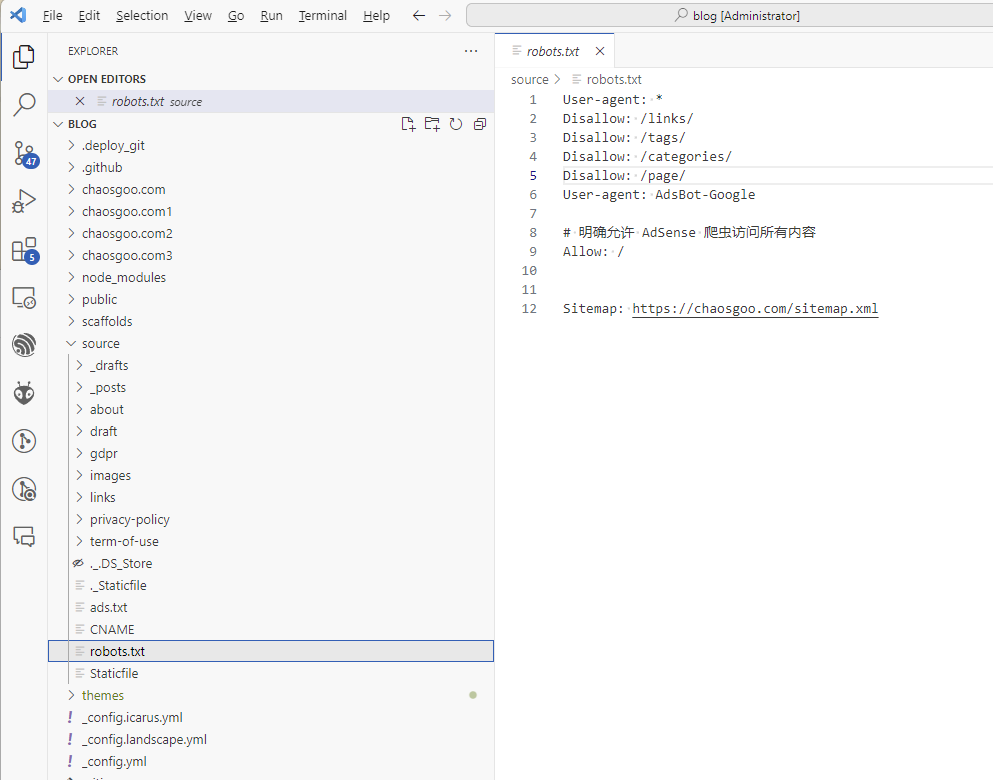
#3:地图混乱(Sitemap 白名单)
虽然我们已经手动编写了robots.txt规则告诉谷歌不要再抓取指定的内容了, 但是在站点地图中依旧存在这些内容.
为了保证内容规范统一, 就需要对不想要的内容标记,让他不要出现在sitemap中.
hexo-generator-sitemap插件安装
我的博客使用的是hexo生成, 所以使用hexo专用的sitemap生成工具, hexo-generator-sitemap
安装很简单,只需要在博客源文件根目录输入
1 | npm install hexo-generator-sitemap --save |
hexo-generator-sitemap使用
使用起来也很简单, 只需要在根目录的_config.yml配置规则即可.
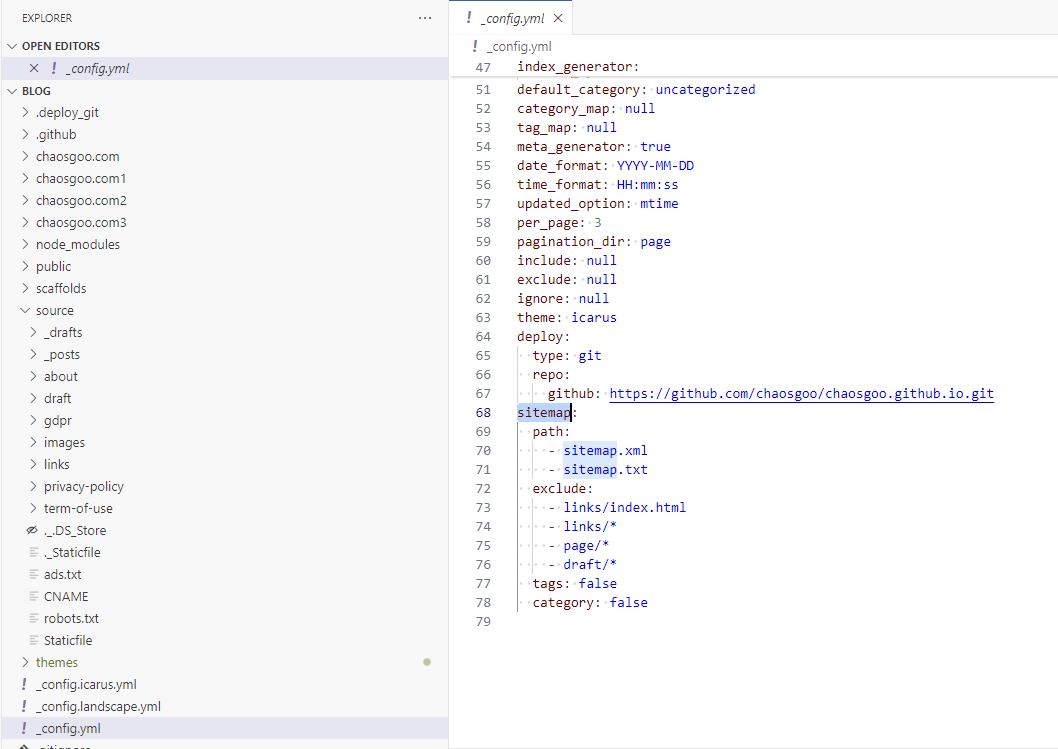
这个插件会在hexo g的时候自动生成一份对于的站点地图.
#4:修复Canonical (致命错误)
你是否还记得前面GSC 的“最终审判”一节提到的网页未纳入联系:重复网页,用户未选择规范网页
这是因为我们的网站页面缺少canonical标记, 谷歌不知道blog.和root版本哪一个才是规范网页, 然后根据经验选择了早就收录的blog.版本作为规范出现在搜索结果中.
排查
因为一般而言,hexo的主题会为我们自动生成canonical标记才对.
所以我打开站点主页, 按F12审查元素发现主页确实没有canonical标记, 但是随便点开几篇文章却又看到了canonical标记, 这就很诡异了.
我以为是‘僵尸缓存’(db.json),清理之后重新生成页面检查, 还是没有canonical标记.
难道是 _config.yml 里的 url 没配置, 也不对, 因为我早就配置了这个属性.
于是决定搜索源码检查这个东西的生成规则.
手动标记canonical
在我的主题生成canonical标记的代码逻辑是,
主页没有page这个概念, 这里的三元运算符算出null, 所以需要手动修改此处逻辑为
1 | // 修改前 (Bug): 主页的 page.permalink 为空,导致 canonical 为空 |
保存后重新生成页面本地部署, 使用F12审查元素成功看到了主页也有了canonical标记, 终于大功告成了.
重新部署站点
现在我们修复了博客的robots.txt和sitemap.xml以及canonical标记, 可以重新部署了.
行动三:推 Google 一把,更新“记忆”
光改完代码还没完,我得主动告诉 GSC 把旧的、乱的索引删掉。
为了加快修复, 我们可以在Google Search Console上主动告诉谷歌sitemap在哪, 以及rotots.txt规则可以重新抓取了
申请重新抓取robots.txt
主动提交sitemap.xml文件
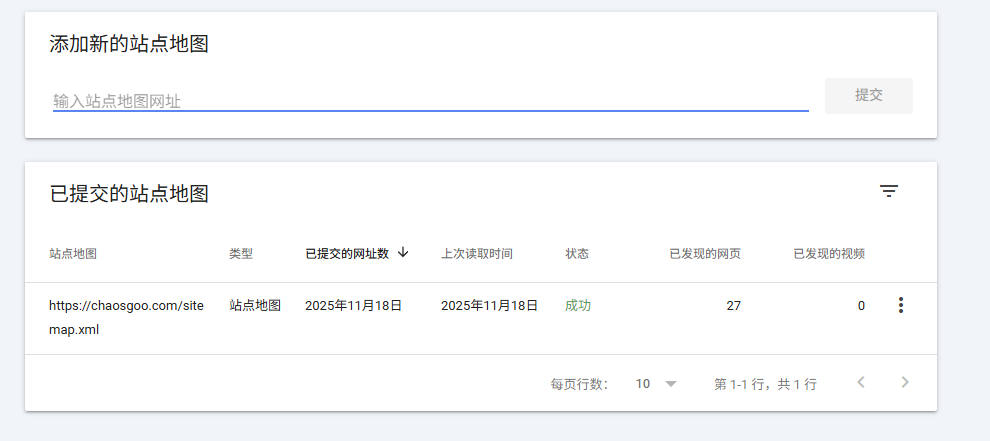
提交隐藏搜索结果申请
还可以使用移除功能, 将不需要的网页移除.
这里我希望把tags, links之类的内容移除, 所以创建了如下的请求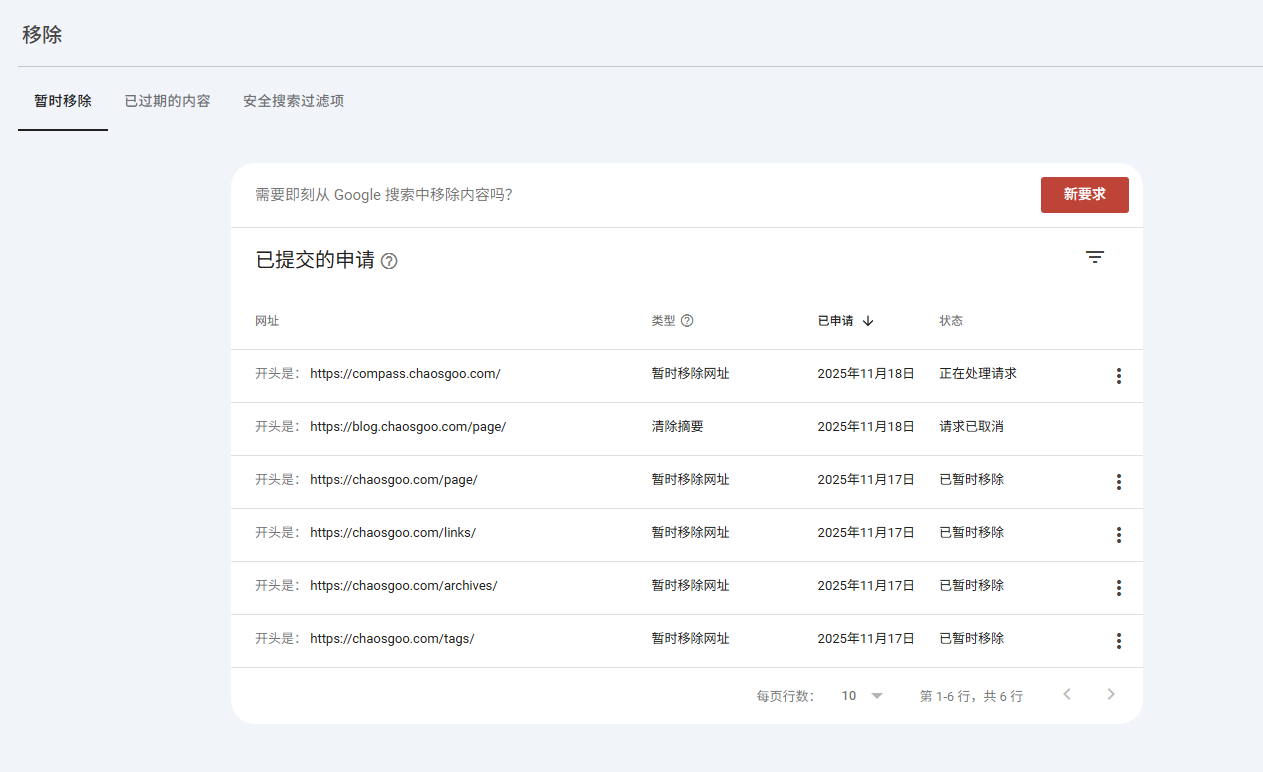
总结
在做了上述操作后, 剩下的就是耐心等待谷歌的机器人抓取网页, 大概过了2天.
我审查网页的时候看到root域名已经被正确收录了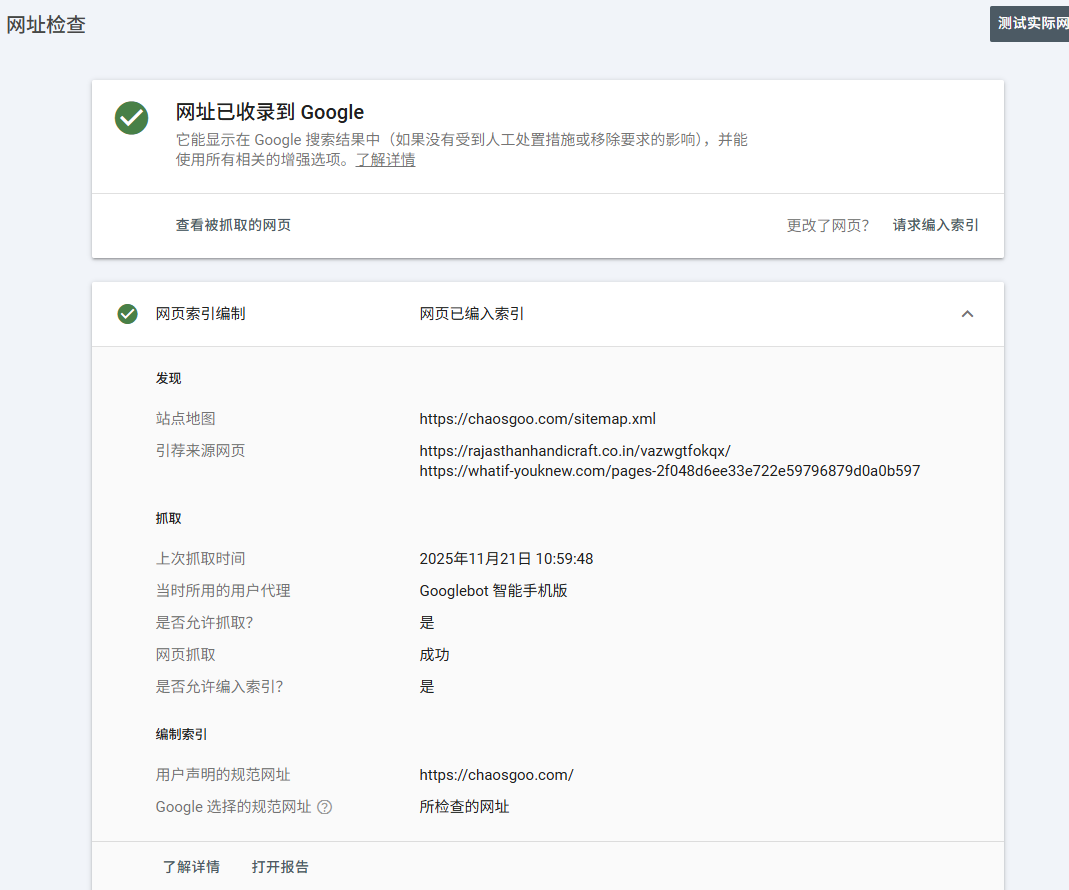
并且site:命令内容也变得干净许多, 基本上只剩下少部分blog.的连接了.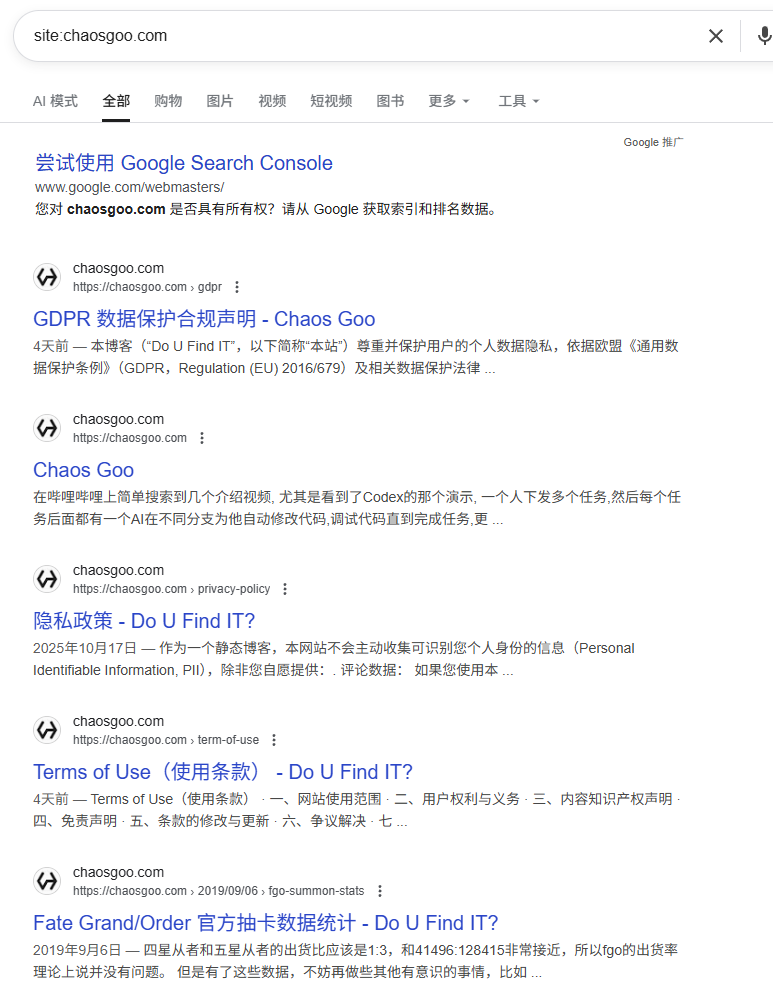
这次排查让我明白,SEO 不是玄学,而是对细节的极致把控。虽然 AdSense 申请还在路上,但看着 GSC 里那条昂扬向上的收录曲线,我知道,我已经准备好了。
为 AdSense 铺路:我如何修复 'GSC 重复网页' 与 Canonical 致命错误(Hexo, 301, robots 详解)
